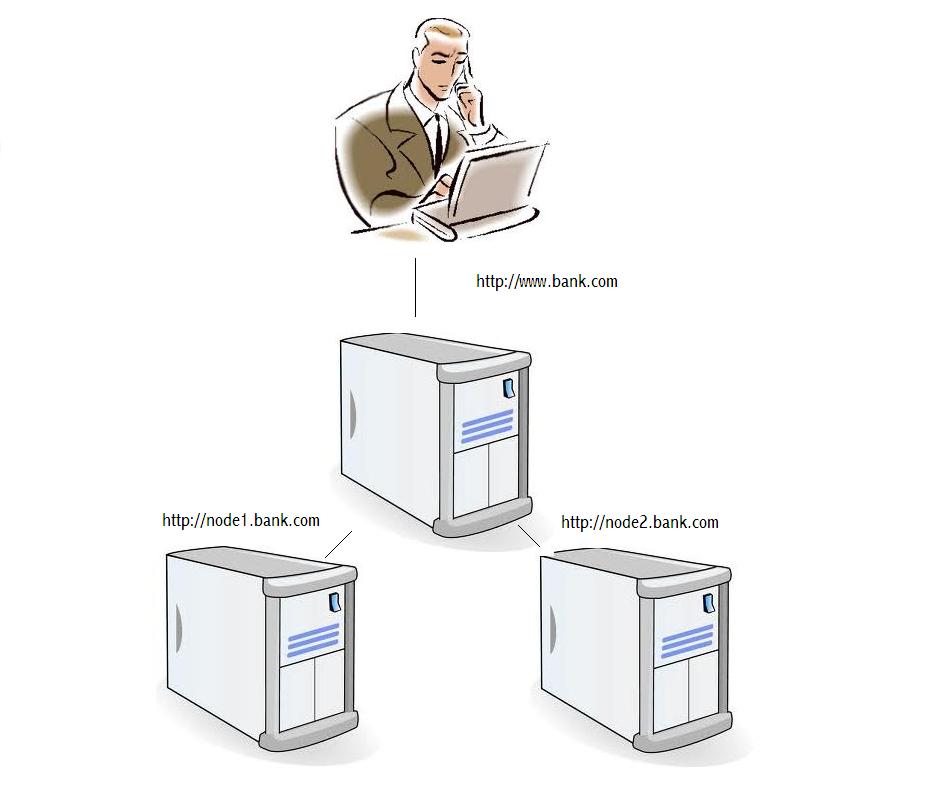
Hardware clustering is frequently used in computer systems where high availability and scalability are needed. In horizontal clustering the same application software is typically installed on multiple identical nodes. For web applications load balancing software such as Cisco’s ‘Global Site Selector’ is used to direct client requests to nodes based on rules (fig 1). The logic may be complicated e.g. based on heartbeats, heuristic load balancing etc. or simple such as ‘route everything to node2 because scheduled maintenance is planned for node1′.
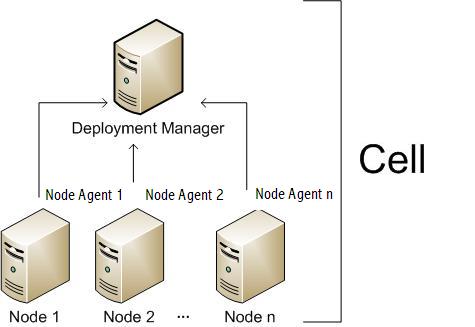
In a clustered Websphere JEE environment, developers deliver the application as an EAR file and the deployment team use the Deployment Manager & Node Agents to reliably install the EAR identically to the different nodes (fig 2).
But what if the same application (EAR) works on one node but not on another? How can that be? The EAR files and nodes are identical!
A clue may be found by turning on verbose class loading. In the Websphere 6 and 6.1 admin console you would do this by following the path Server > Application Server > your server name > Process Definition > Java Virtual Machine and selecting the ‘Verbose Garbage Collection’ checkbox. Every class that is loaded together with where it is loaded from (normally a .jar file) is listed to the SystemOut.log file.
By deleting the log file, starting the server and carefully replaying the steps up to the node specific error one can see exactly which classes were called on each node. The classes might not be loaded in the same order! On inspection the JAR files are loaded in the same order as listed by the unix command ‘find’.
Why might ‘find’ deliver different results? Imagine that the developers delivered 2 versions of the application. In version 1 everything is in a.jar but in version 2 some ‘base’ classes were moved to b.jar. Version 1 was installed to node1 but never installed to node2. Later version 2 was installed to both nodes bringing us to the ‘identical’ state. We can reproduce the deployment without even needing multiple nodes; just a couple of directories and some copy commands as below:
~ $ mkdir playpen ~ $ cd playpen ~/playpen $ ls ~/playpen $ touch a.jar b.jar ~/playpen $ mkdir node1 node2 ~/playpen $ cp a.jar node1 ~/playpen $ cp b.jar a.jar node2 ~/playpen $ cp b.jar a.jar node1 ~/playpen $ cd node1 ~/playpen/node1 $ find . -name "*.jar" ./a.jar ./b.jar ~/playpen/node1 $ cd ../node2 ~/playpen/node2 $ find . -name "*.jar" ./b.jar ./a.jar ~/playpen/node2 $
‘find’ has delivered the files in their i-node order i.e. when they were first created (not overwritten) as can be seen clearly using ‘ls –i’:
~/playpen/node2 $ cd .. ~/playpen $ ls -i node1 16677851 a.jar 16677854 b.jar ~/playpen $ ls -i node2 16677853 a.jar 16677852 b.jar
If a.jar and b.jar contain classes with identical names and packaging but different behaviour we have a problem. When one considers the size and number of JAR files in a typical enterprise application together with the potential for different versions of the same JAR, cluster nodes (or indeed software versions running on ‘identical’ environments such acceptance test and production) may not be as equal as they seem at all. A possible solution would be to always install all versions of the software to every node in the cluster (in the right order) or to completely wipe (clean) every deployment including parent directories for every deployment.
References:
http://en.wikipedia.org/wiki/High-availability_cluster
http://www.cisco.com/en/US/products/hw/contnetw/ps4162/index.html
http://itdevworld.wordpress.com/2009/05/03/websphere-concepts-cell-node-cluster-server/
http://www-01.ibm.com/support/docview.wss?uid=swg21114927#v6